
Google опублікувала дані про створення інноваційного алгоритму діаризації – поділу вхідного аудіопотоку на однорідні сегменти відповідно до належності слів тій чи іншій людині. Компанія стверджує, що створена технологія більш ефективна, ніж відомі раніше.

Розробка базується на рекурентній нейронній мережі (RNN). Така архітектура дозволяє використовувати внутрішню пам’ять для обробки послідовностей довільної довжини і добре підходить для роботи з розбитих на сегменти аудіопотоку. У розробці Google для кожного мовця виділяється окремий екземпляр RNN, що виокремлює висловлювання.
Спеціалісти звертають увагу, що їх алгоритм є повністю прозорим і контрольованим, що дозволяє коригувати процес обробки аудіопотоку.
Розробники перевірили ефективність нового алгоритму діаризації за допомогою тесту NIST SRE 2000 CALLHOME. Похибка визначення склала 7,6 %. Використовувані раніше методи кластеризації і виділення за допомогою нейронної мережі показували похибку 8,8% і 9,9% відповідно. Крім меншої кількості помилок алгоритм володіє продуктивністю, достатньою для обробки потоку в реальному часі.
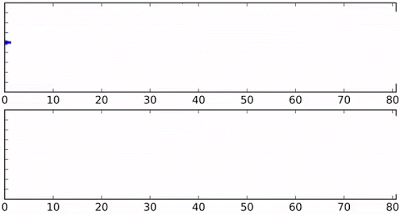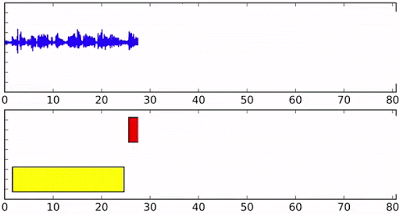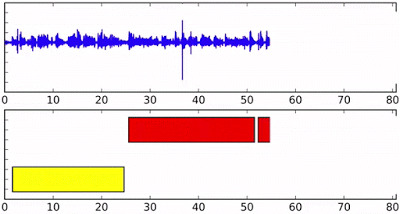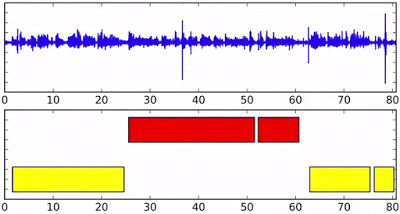
Визначення приналежності реплік — важливий компонент системи розпізнавання мови. Коректна диаризация дозволяє краще пристосуватися до особливостей вимови і акценту і якісно розділити висловлювання різних людей. Технологія знайде застосування, зокрема, у створенні субтитрів до відеозаписів. Правильно розпізнану мову легше перевести на інші мови, що, наприклад, буде корисно для онлайнових навчальних курсів. А можливість обробляти звук в реальному часі дозволить робити це навіть в прямому ефірі.
Для залучення в процес вдосконалення алгоритму діаризації якомога більшої кількості фахівців Google випустила продукт під відкритою ліцензією і розмістила його в репозиторії GitHub.
Google активно розвиває технології розпізнавання мови і привертає до цього процесу сторонніх розробників. У квітні 2017 року компанія відкрила доступ до Cloud Speech API — технології розпізнавання мови, що лежить в основі Google Асистента.





