
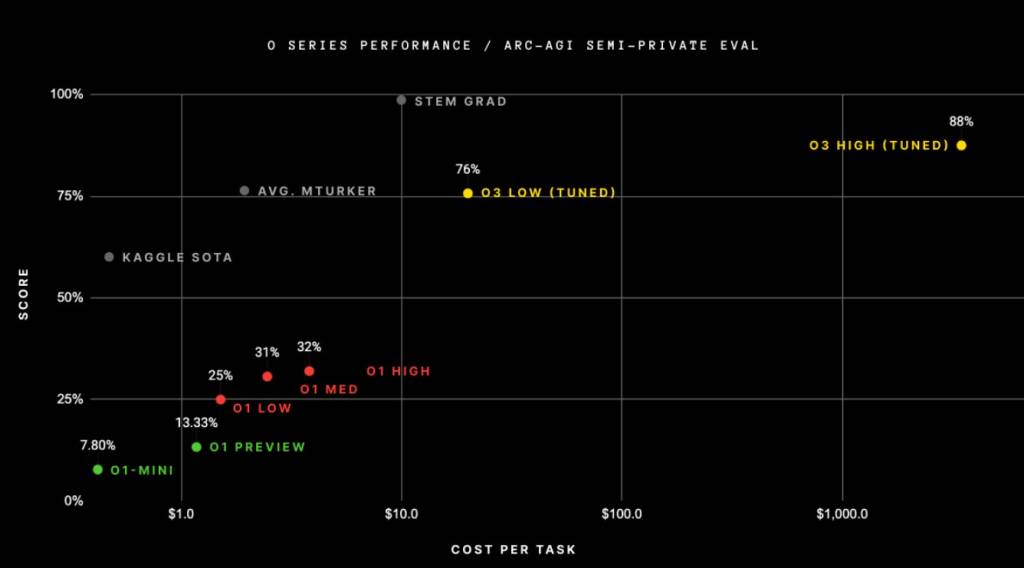
Нова модель OpenAI, o3, досягла безпрецедентних результатів, набравши 75,7% у складному тесті ARC-AGI за стандартних обчислювальних умов, а в версії з високою продуктивністю – 87,5%. Це стало сенсацією в дослідницькому співтоваристві ШІ, оскільки тест ARC-AGI перевіряє здатність систем ШІ адаптуватися до нових завдань, демонструючи гнучкий інтелект. Тест включає візуальні головоломки, що потребують розуміння базових концепцій, таких як об’єкти, межі та просторові відносини, що робить його одним із найскладніших для оцінки можливостей ШІ.
Що варто знати про o3
ARC-AGI складається з публічних тренувальних та оціночних наборів даних, а також закритих тестів, що не розголошуються. Це гарантує, що системи не можуть просто «обдурити» процес, навчаючись на мільйонах прикладів. Окрім цього, тест обмежує кількість обчислень, що запобігає використанню методу «грубої сили» для вирішення головоломок.
Попередні моделі o1-preview та o1 досягли максимального результату лише 32% у цьому тесті, тоді як метод, розроблений дослідником Джеремі Берманом, досяг 53% за допомогою комбінації Claude 3.5 Sonnet, генетичних алгоритмів та інтерпретатора коду.
Франсуа Шолле, творець тесту ARC, описав результат o3 як «визначний стрибок у розвитку ШІ, що демонструє безпрецедентну здатність до адаптації». За його словами, попередні моделі не могли досягти таких результатів навіть за рахунок більш потужних обчислювальних ресурсів.

Однак успіх o3 був досягнутий за рахунок великих витрат. У стандартній конфігурації модель витрачає від $17 до $20 та 33 мільйони токенів на вирішення кожної головоломки, в той час як в режимі високої продуктивності обчислювальні ресурси зростають в 172 рази, а модель використовує мільярди токенів на кожне завдання.
Ключовим фактором у досягненні таких результатів, за словами Шолле та інших вчених, є «синтез програм». Це означає, що система має здатність створювати малі програми для вирішення конкретних проблем і поєднувати їх для більш складних завдань. Класичні мовні моделі мають великий набір знань, але їм бракує здатності до композиційності, що обмежує їх здатність вирішувати задачі, які виходять за межі навчальних даних.
Деталі того, як працює o3, залишаються частково незрозумілими, і думки вчених розходяться. Шолле припускає, що o3 використовує метод синтезу програм, комбінуючи ланцюжкове міркування з механізмом пошуку та моделлю винагороди для уточнення результатів. Інші вчені, зокрема Натан Ламберт, вважають, що o3 є розвитком попередніх моделей, таких як o1, з подальшим масштабуванням навчання з підкріпленням.
Хоча деталі процесу міркування o3 важливі, їх значення може бути не таке важливе в контексті прориву в ARC-AGI, який відкриває нові можливості для ШІ. Одним з ключових питань є те, чи досягнули LLM-моделі межі масштабування, чи наступні прориви будуть залежати від нових архітектур або даних.
Не слід забувати, що ARC-AGI не є тестом для визначення AGI. Шолле підкреслює, що навіть після успіху o3, ця модель ще не є AGI, оскільки вона не справляється з простими завданнями, що свідчить про фундаментальні відмінності від людського інтелекту.
Водночас деякі вчені звертають увагу на певні обмеження результатів o3, зокрема на те, що модель була тонко налаштована на тренувальний набір ARC для досягнення таких результатів. Для перевірки гнучкості цих моделей у вирішенні завдань з різними варіаціями Мелані Мітчелл пропонує використовувати інші сценарії, щоб перевірити здатність до адаптації систем.
Шолле та його команда працюють над новим тестом, який може значно ускладнити o3, знижуючи її оцінку навіть до 30% при високих обчислювальних витратах, тоді як люди зможуть вирішити більшість головоломок без навчання.





